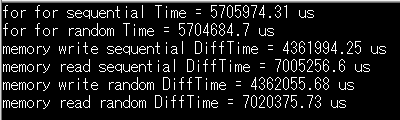
前回の記事では、exStickGE上でソフトプロセッサであるMicroBlazeを動かしてみました。今回は、DRAMアクセスにかかる時間について、アクセスの仕方で速度が多少なりとも変わるのかについて調べました。
検証
速度計測のプログラムは前回のものを踏襲しつつ、メモリアドレスをシーケンシャルに4バイト(int分)ずつインクリメントしながらアクセスする場合と、大きくストライドをとってアクセスする場合の実行時間を比較できるように修正しました。これは、たとえば、2次元配列の行優先でアクセスするか列優先でアクセスするかの違いに相当します。アクセスするメモリ領域は64MBの範囲です。
読み書きするためのforループ分を事前に空で回してその分を引いておくことで、純粋な読み書き時間を測定しようと目論んでいます。
作成したプログラムです(main関数抜粋)。
int main()
{
volatile unsigned int i,j,addr,read_tmp;
u32 tStart, tEnd;
u32 timeoffset_seq, timeoffset_rand;
init_platform();
init_timer();
print("\033[2J\033[1;1H");
//Measure Time offset
print("for for sequential ");
tStart = XTmrCtr_GetValue(&TimerCounterInst, 0);
for(i=0;i<8*1024;i++){
for(j=0;j<8*1024;j+=4){
addr = i*8*1024+j;
}
}
tEnd = XTmrCtr_GetValue(&TimerCounterInst, 0);
show_time_us((unsigned int)(tEnd - tStart));
timeoffset_seq = tEnd - tStart;
print("for for random ");
tStart = XTmrCtr_GetValue(&TimerCounterInst, 0);
for(j=0;j<8*1024;j+=4){
for(i=0;i<8*1024;i++){
addr = i*8*1024+j;
}
}
tEnd = XTmrCtr_GetValue(&TimerCounterInst, 0);
show_time_us((unsigned int)(tEnd - tStart));
timeoffset_rand = tEnd - tStart;
//Write Sequential
print("memory write sequential Diff");
tStart = XTmrCtr_GetValue(&TimerCounterInst, 0);
for(i=0;i<8*1024;i++){
for(j=0;j<8*1024;j+=4){
addr = i*8*1024+j;
MEM_array(addr) = addr;
}
}
tEnd = XTmrCtr_GetValue(&TimerCounterInst, 0);
show_time_us((unsigned int)(tEnd - tStart - timeoffset_seq));
//Read Sequential
print("memory read sequential Diff");
tStart = XTmrCtr_GetValue(&TimerCounterInst, 0);
for(i=0;i<8*1024;i++){
for(j=0;j<8*1024;j+=4){
addr = i*8*1024+j;
read_tmp = MEM_array(addr);
}
}
tEnd = XTmrCtr_GetValue(&TimerCounterInst, 0);
show_time_us((unsigned int)(tEnd - tStart - timeoffset_seq));
//Write Random
print("memory write random Diff");
tStart = XTmrCtr_GetValue(&TimerCounterInst, 0);
for(j=0;j<8*1024;j+=4){
for(i=0;i<8*1024;i++){
addr = i*8*1024+j;
MEM_array(addr) = addr;
}
}
tEnd = XTmrCtr_GetValue(&TimerCounterInst, 0);
show_time_us((unsigned int)(tEnd - tStart - timeoffset_rand));
//Read Random
print("memory read random Diff");
tStart = XTmrCtr_GetValue(&TimerCounterInst, 0);
for(j=0;j<8*1024;j+=4){
for(i=0;i<8*1024;i++){
addr = i*8*1024+j;
read_tmp = MEM_array(addr);
}
}
tEnd = XTmrCtr_GetValue(&TimerCounterInst, 0);
show_time_us((unsigned int)(tEnd - tStart - timeoffset_rand));
cleanup_platform();
return 0;
}
計測結果
事前にforループ分を測定した時間(1,2行目)を抜いた結果が3-6行目です。
結果をミリ秒単位に切り上げて表にしました。
結果からアドレス指定の方法の違いによる実行時間の差はほぼないことがわかります。
| 読み込み | 書き込み | forループの処理時間(オフセットとして引いた分) | |
| 連続 | 7005 ms | 4362 ms | 5706 ms |
| ランダム | 7020 ms | 4362 ms | 5705 ms |
書き込み時
書き込み時のAXIトランザクションを見てみましょう。
連続書き込み

ランダム書き込み

MIGのAXIアドレスは0x80000000で4バイトずつアドレス発行していることが見えます。
書き込むたびにAXIトランザクションが発行されているため、連続のアドレスへ書き込みを行ったとしてもバースト転送されるわけでもなくメリットがないと考えられます。
ランダムに書き込んでいる場合のトランザクションとも比較してみますが、WREADYが立ち上がるタイミングも同じであることから全く同じ挙動であることがわかりました。
ILAを見ると、およそ60サイクルに一度、データ書き込みのAXIトランザクションが実行されています。ILAのクロックが100MHzなので、これは60n秒に相当します。
16M回の書き込みループの総実行時間は9969m秒、つまり1回あたりの書き込み時間は594.2n秒。これはILAの観測結果とほぼ一致することがわかります。
アドレス指定(AWVALIDのアサート)からトランザクション終了(BVALIDのアサート)までが約15サイクル(= 150n秒)です。これはforループのオフセット分を引いた書き込み時間を16M回で割った約256n秒より小さく、MicroBlazeから見たデータ書き込み時間内でAXIトランザクションがちゃんと終了していることがわかります。すなわち、簡易的にはMicroBlazeでDRAMにデータを書き込むのにかかる時間は256n秒と見て良さそうです。
読み込み
同様に読み込み時のAXIトランザクションを見てみます。
連続読み込み

ランダム読み込み

基本的には同じ挙動をしています。書き込みより長い時間がかかっているのは、書き込みであればメモリに書き込んでおいてね!で終わるのに対して読み込みアドレスを投げてから実際に読み出しをしなければいけないことによる違いですね。
ILAを見ると、読み出しトランザクションはおよそ75サイクルに一度発行されています(上の図だと75サイクルと76サイクルが見えている)。つまり1回あたりの読み出し時間はおよそ750n秒です。
実行時間の計測結果では、16M回の読み出しに12612m秒かかっていますので、一回あたりの読み出し時間は751.7n秒。これもILAの観測結果と一致していることがわかります。
アドレス指定(ARVALIDのアサート)からトランザクション終了(RVALIDのアサート)までが約31サイクル(= 310n秒)です。これはforループのオフセット分を引いた書き込み時間を16M回で割った約418n秒より小さく、MicroBlazeから見たデータ書き込み時間内でAXIトランザクションがちゃんと終了していることがわかります。すなわち、簡易的にはMicroBlazeでDRAMからデータを読み出すのにかかる時間は418n秒と見て良さそうです。
まとめ
今回は連続とランダムなアドレスに読み書きを行い、その違いについて調べてみました。
読み書き命令に対してその都度AXIトランザクションを発行していることから
アドレスの連続性に関わらず一定の時間がかかってしまうことがわかりました。
逆に考えるとDRAMの読み書き時間はアクセス方法によらずほぼ一定と考えることもできますので、リアルタイム処理を実装する場合にも安心して利用できまると言えます。
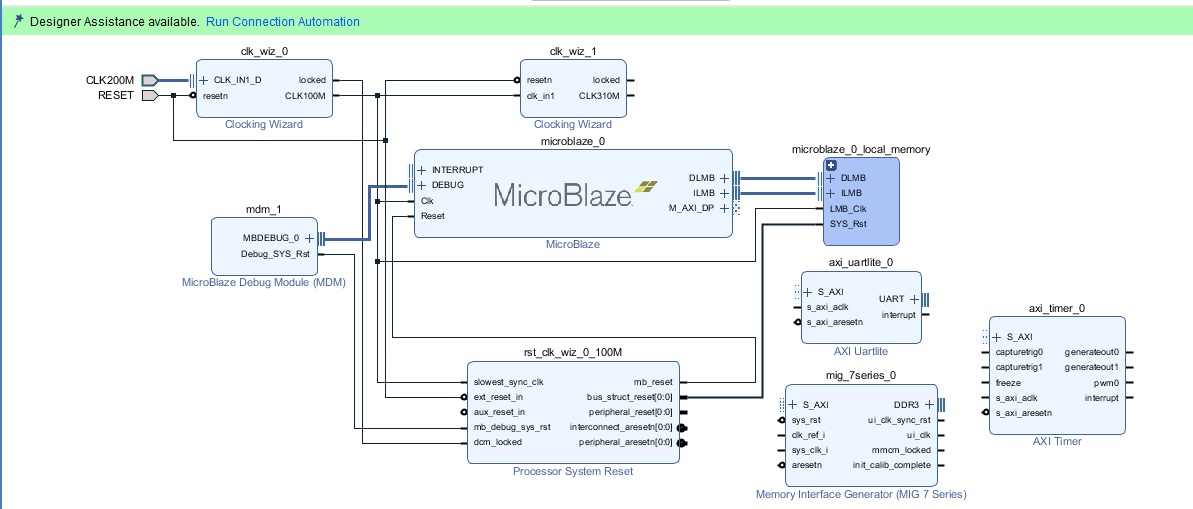
コメント