PCIe gen1 x1の転送速度は理論(規格)上では2.5GTps,0.25GBpsです.
しかし,実際にはPCIe上のデータを駆動するエンジンの処理時間や,データ供給源からの読み出し,書き込み先での書き出し時間など,いろいろなオーバヘッドが入ってきます.
で,実際どのくらいなのよ?というのを EDKでPCIe+DDR3のアクセラレータフレームワークを作る(1) で作ったシステムをベースに評価してみました.
結果
で,いきなりですが,結果です.
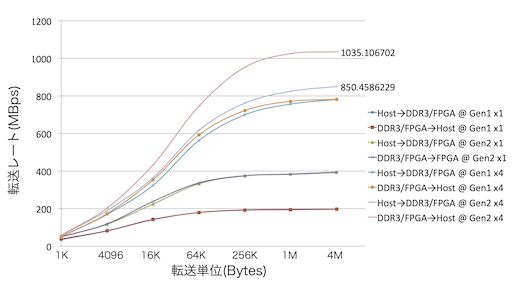
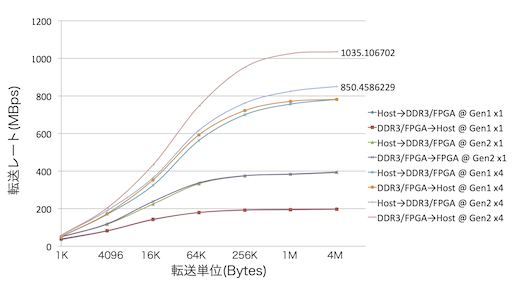
測定したのは,
転送速度は次の4パタン,
- Gen1 x1
- Gen2 x1
- Gen1 x4
- Gen2 x4
DMA転送単位は次の7パタンを試しました
- 1KB
- 4KB
- 16KB
- 64KB
- 256KB
- 1MB
- 4MB
Gen2 x4の場合は,
- DMA転送単位が1KBのときにHost→DDR3/FPGAとDDR3/FPGA→Hostのどちらも約58MBps
- DMA転送単位が4MBのときにHost→DDR3/FPGAが約850MBps,DDR3/FPGA→Hostが約1035MBps
でした.
結構速いと思うのですが,PCIeの理論的な転送レートはGen2 x4の場合2GBpsなので,それからすると半分くらいの速度がでいてるということになります.
もう少し詳しく考えてみましょう.
結果について考える前に,評価した環境を示しておきます.
実験するシステムのコンポーネント構成
実験に用いるシステムのコンポーネント構成は次の通りで,これは,単純にEDKのAXI I/Fなコアを組み合わせたシステムです.
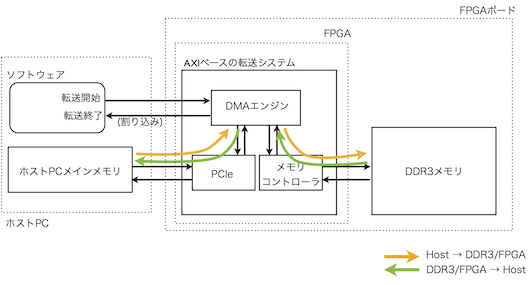
評価の動作は,
- ソフトウェアがDMAに適切なパラメタをセット
- DMAを開始(ここが開始時刻)
- 終わったら割り込みがかかるので,その時刻が終了時刻
- 終了時刻-開始時刻がデータの転送にかかった時間
- ホストPCのメモリの内容をFPGAボードのメモリに書き込む(Host→DDR3/FPGA)
- FPGAボードのメモリの内容をホストPCのメモリに書き込む(DDR3/FPGA→Host)
ホストPCのスペック
実験に使ったホストPCの素性は,こんな感じ.
- CPU:Core i5-4430
- マザーボード:GA-Z87X-UD5H セット
- メモリ:CML32GX3M4A1600C10B (PC3-12800/DDR3-1600)
FPGAボード関連のスペック
FPGA側のパラメタは,こんな感じ.
- FPGAボード:Xilinx KC705
- メモリ:MT8JTF12864HZ-1G6G1(データパス幅 64bit,最大転送レート: 1600MT/s)
- AXIまわりのパラメタ
- クロック
- CDMAなどの基本的な回路 100MHz
- メモリ 800MHz (200MHzを1:4で供給)
- PCIe 100MHz(供給クロック)→125MHz(内部処理クロック)
- データ幅
- AXIメインネットワーク 256bit
- PCIeデータ幅 128bit
- メモリコアへのAXIバス幅 256bit
- クロック
結果をよく眺めてみよう
PCIeの転送速度が,Gen1 x1,Gen2 x1,Gen1 x4,Gen2 x4で1,2,4,8倍になっていて,メモリやオペレーション処理にかかる時間がPCIeの転送速度と無関係だと仮定してみます.
すると,xバイトのデータを転送するのにかかる時間yは,Gen1 x1の転送レートをa,メモリやオペレーション処理にかかる時間をbとすると,
- Gen1 x1: y = x/a + b
- Gen2 x1: y = x/2a + b
- Gen1 x4: y = x/4a + b
- Gen2 x4: y = x/8a + b
になります.先の実験値を元に最小二乗法でaとbを求めてみましょう.xは1 Byte,yはスループットの逆数です.
転送単位が1024BytesのHost→DDR3/FPGAの場合は↓のように
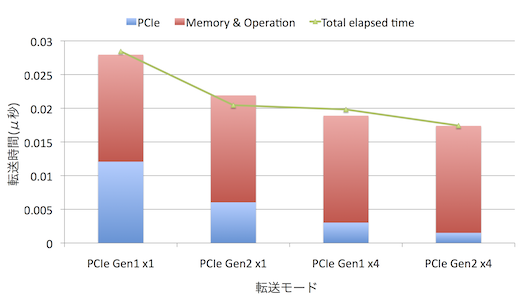
転送単位が4MBytesのHost→DDR3/FPGAの場合は↓のように
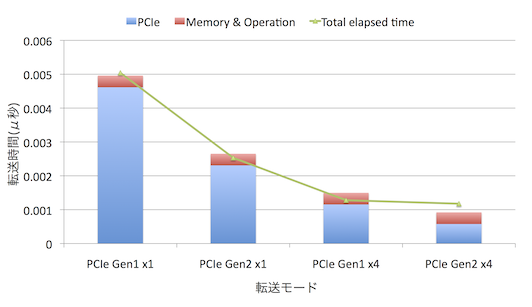
なりました.
積み上げグラフの赤の部分と青の部分が,それぞれ,計算で求めたPCIeの転送時間とメモリアクセスやその他の処理にかかった時間に相当します.また,緑の折れ線が実験値です(1 Bytesの転送にかかる時間).
傾向として大きくずれてはいないので,”PCIeの転送時間はスケールしている”,”メモリアクセスとオペレーションの時間は一定”という上記の仮定は大きく間違ってはいないようです.
ちなみに,計算で求めた4MByteのときのPCIeの転送レートは,理論性能の86%程度でした.うーん,まあ,こんなものかなぁ,と.
結果を踏まえて
システムとしては4KBくらいの転送単位のなら50MBpsくらい,4MBくらいの転送単位なら1GBpsくらいですよー,という感じでいいのかな.
小さなデータ転送が多いようなアプリでも,256KBから512KB単位での転送ができるようにするといいのかも.
また,最初に示した測定結果,そして上記の積み上げグラフをみてみると,PCIe gen2 x8やPCIe gen3 x4といった,もう一つ上のグレード,あるいは,それ以上を採用しても,システムとしては単純に倍の性能が得られる,というわけではないのかな,ということも言えそうですね.


コメント