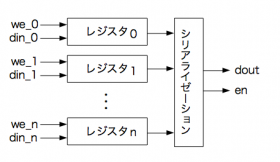
データ並列性が活用できる処理では,並行処理した結果を,それぞれのレジスタに格納しておいて最終的にそれをシリアライゼーションして取り出したい,というケースがままあります.
FPGAが大規模になって,かなりたくさんの処理を並べられるなってきた今日このごろ,問題になりそうなのが結果のシリアライゼーションどうするか,という話.
たくさんのレジスタを順になめていくような回路を作ってしまうとマルチプレクサがばかでかくなってしまうように思われます.それを回避するために,たとえばシフトレジスタ的に読み出すようにすればいいかもしれません.実際のところ,どうなの?というのを試してみました.
作りたい回路
おさらいすると,作りたい回路はこんな感じ.
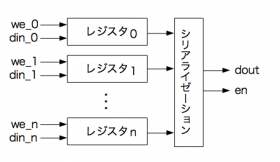
マルチプレクサで選択する場合には,シリアライゼーションの部分で,カウンタをつかって,レジスタ0〜nまでを順に出力することになります.nが大きい場合には,大きなマルチプレクサが必要になってしまいますね.
シフトレジスタだと
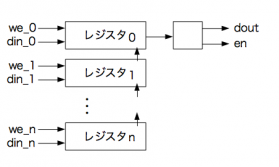
こうなります.直感的にはnが大きくなっても問題ないように見えますね.
RTL記述
簡単のため,Synthesijer.ScalaでRTL設計します.
マルチプレクサ版はこんな感じ.
// dataの配列がレジスタファイルの実体
private val data = for(i <- 0 until depth) yield{ signal("reg_" + i, width) }
private val seq = sequencer("seq")
private val counter = signal(32);
counter.reset(VECTOR_ZERO); counter.default(VECTOR_ZERO)
// MUX: カウンタで指定されたレジスタファイルの値をmax_outに出力
private var mux_out:ExprItem = VECTOR_ZERO
for(i <- 0 until depth; d = data(i)){ mux_out = ?(counter == i, d, mux_out) }
// IDLE: シリアライゼーション開始(kick='1')までは
// それぞれのレジスタファイルへの入力をクロックに同期して取り込む
for(i <- 0 until depth){ data(i) <= seq.idle * ?(we(i), din(i), data(i)) }
counter <= seq.idle * ?(kick, value(1, counter.width()), value(0, counter.width()))
offset <= seq.idle * counter;
dout <= seq.idle * mux_out
en <= seq.idle * kick
private val s0 = seq.idle * kick -> seq.add()
// S0: シリアライゼーション処理
dout <= s0 * mux_out
en <= s0 * HIGH
offset <= s0 * counter;
counter <= s0 * (counter + 1)
private val s1 = s0 * (counter == depth-1) -> seq.add()
// S1: カウンタやフラグの後処理
s1 -> seq.idle
シフトレジスタ版はこんな感じ.
// dataの配列がレジスタファイルの実体
private val data = for(i <- 0 until depth) yield{ signal("reg_" + i, width) }
private val seq = sequencer("seq")
private val counter = signal(32);
counter.reset(VECTOR_ZERO); counter.default(VECTOR_ZERO)
// IDLE: シリアライゼーション開始までは入力データを取り込む
counter <= seq.idle * ?(kick, value(1, counter.width()), value(0, counter.width()))
dout <= seq.idle * data(0)
en <= seq.idle * kick
offset <= seq.idle * counter
for(i <- 0 until depth){
val d = if (i == depth-1) VECTOR_ZERO else data(i+1) // 最後以外は一つ後のデータ
data(i) <= seq.idle * ?(kick == HIGH, d, // シリアライゼーション開始で一つずつシフト
?(kick == LOW and we(i) == HIGH, din(i), // input data
data(i))) // as is
}
private val s0 = seq.idle * kick -> seq.add()
// S0: シリアライゼーション処理本体
dout <= s0 * data(0)
offset <= s0 * counter
for(i <- 0 until depth){
val d = if (i == depth-1) VECTOR_ZERO else data(i+1) // 最後以外は一つ後のデータ
data(i) <= s0 * d // シリアライゼーション中は一つずつシフト
}
en <= s0 * HIGH
counter <= s0 * (counter + 1)
private val s1 = s0 * (counter == depth-1) -> seq.add()
// S1: フラグとカウンタの後始末に1クロック
s1 -> seq.idle
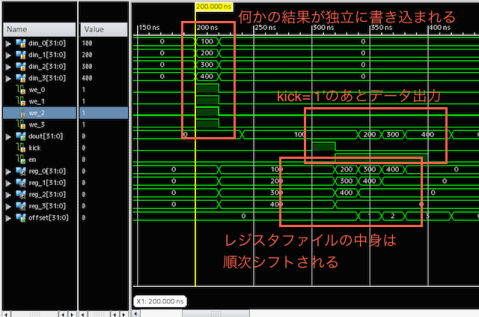
たとえば,レジスタの数が4個の場合のシフトレジスタ版の動作をシミュレーションしてみると,こんな感じ.結果がシリアライゼーションして出力されることが確認できます.
合成してみる
ISE14.7で,KC705のXC7K325T-2をターゲットFPGAとして合成してみることにします.ワード数は,強気の1000個.計算はなしで入出力はI/Oピンに出すことにします.ただし,独立に1000本の32bitデータを入力させるにはピン数が足りないので,入力側はアドレスでデコードします.さらに,1000出力のデコードを一度に行うのはファンアウト的に厳しいので,16個にコピーした上で割り振りました.
Synthesijer.Scala的には,こんな感じ.
// 外部からのアドレス入力を16個にコピー
val addr_d = for(i <- 0 until 16; val s = signal(addr.width())) yield{
s $ sysClk := addr; s
}
// 外部からのデータ入力を16個にコピー
val din_d = for(i <- 0 until 16; val s = signal(din.width())) yield{
s $ sysClk := din; s
}
// mod 16でアドレス,データを利用してレジスタファイルにデータを書く
for(i <- 0 until m.depth){
inst.signalFor(m.din(i)) $ sysClk := din_d(i % 16)
inst.signalFor(m.we(i)) $ sysClk := ?(addr_d(i % 16) == value(i, 32), HIGH, LOW)
}
結果
リソース使用量
レジスタは,どちらもおよそ32*1000個と想定通りです(当たり前).シフトジスタ版ではLUTがレジスタとほぼ同数必要になります.ただし,使用スライス数は,どちらも同じ程度.これはシフトレジスタ版のレジスタとLUTが,ほぼ100%,同じスライスにマッピングされるからです.
動作周波数
200MHzで制約をかけて合成したところ,マルチプレクス版はワーストケースが5.093n秒とタイミングメットしませんでした.一方シフトレジスタ版は4.6n秒と余裕.
シフトレジスタ版に,制約を3.3n秒に設定して合成すると,ワーストケース3.09n秒と,これまた,かなりいい感じです.
最後に
PlanAheadでみてみると,まだ最適化の余地もありそうな気も…時間をみつけて,こういうアプリケーションでよく使うパタンというののライブラリを充実させていきたいものです.
あ,今回はXilinxでのプチ実験でしたが,Altera版もやっておこう.
ちなみに,合成に利用したソースコードは,それぞれ次の通りです.
- マルチプレクサ版 registerfile_with_read_mux.scala
- シフトレジスタ版 registerfile_with_read_scanner.scala


コメント