GbE版のe7UDP/IPを使ってPCからFPGAにパケットを送って返ってくるまでのレイテンシをはかってみました.
注: あくまで,この数字は今回はかってみたという範囲での測定結果です.測定結果は十分に検証されてものではありませんので,ご容赦ください.
測定(1)
測定環境
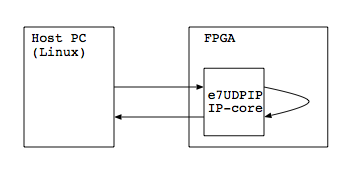
測定環境として用意したのはこんな感じの構成
Linuxが走っているホストPCから,FPGAにUDPパケットを投げて返ってくるまでの時間を測定します.パケットは,FPGA内部でプロトコル処理をされた後で,折り返されていることに注意してください.実験に使ったPCのスペックは次の通り.
CPU Core i7-3770K 3.50GHz メモリ 32GB OS CentOS 6.6 (Linux kernel 2.6.32) ネットワークI/F Intel 82572EI GbE コンパイラ gcc 4.4.7
測定に使ったプログラム
単純にUDPパケットを作って投げて受信するというのを繰り返すだけのプログラムです.ただし,(1)ソケットのオープン/クローズを含む場合(SOCK_ONETIMEを定義しない場合),と,(2)ソケートのオープン/クローズは含まない場合(SOCK_ONETIMEを定義する場合),で測定してみます.
測定結果は,それぞれ100,000回の送受信を繰り返すのにかかった時間を測定し,その時間を100,000で割った値を1回の送受信にかかるレイテンシとみなしています.
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <sys/time.h>
double get_time(){
struct timeval t;
double usec;
gettimeofday( &t, NULL );
usec = t.tv_sec + t.tv_usec / 1000000.0;
return usec;
}
int main(int argc, char** argv){
int sock, i;
struct sockaddr_in addr;
char b0[1024];
char b1[1024];
double t0, t1;
addr.sin_family = AF_INET;
addr.sin_port = htons(16385);
addr.sin_addr.s_addr = inet_addr("10.0.0.1");
#ifdef SOCK_ONETIME
sock = socket(AF_INET, SOCK_DGRAM, 0);
bind(sock, (struct sockaddr *)&addr, sizeof(addr));
#endif
t0 = get_time();
#ifndef TIMES
#define TIMES (100000)
#endif
for(i = 0; i < TIMES; i++){
#ifndef SOCK_ONETIME
sock = socket(AF_INET, SOCK_DGRAM, 0);
bind(sock, (struct sockaddr *)&addr, sizeof(addr));
#endif
sendto(sock, (void*)b0, sizeof(b0), 0, (struct sockaddr *)&addr, sizeof(addr));
recv(sock, (void*)b1, sizeof(b1), 0);
#ifndef SOCK_ONETIME
close(sock);
#endif
}
t1 = get_time();
printf("elapsed time (for %d times)= %lf sec.\n", TIMES, (t1-t0));
printf("elapsed time (for a time)= %lf sec.\n", (t1-t0)/TIMES);
#ifdef SOCK_ONETIME
close(sock);
#endif
return 0;
}
結果
結果は次の通り.まあ,こんなもの,なのでしょうか…
ソケットのオープン/クローズを含む場合 145μ秒 ソケットのオープン/クローズを含まない場合 101μ秒
測定(2)
環境
今度は,間にスイッチを挟んでみる事にします.
使用したスイッチは,PLANEXのFXG-16IRMです.
結果
結果は次の通り.スイッチを挟んだ場合と比べてレイテンシは長くなりました.ところで,ソケットのオープン/クローズを含む場合と含まない場合での差が小さくなったのがちょっと不思議.システムコール呼び出しの間隔が変わったから,とか?もう少し調査が必要です.
ソケットのオープン/クローズを含む場合 159μ秒 ソケットのオープン/クローズを含まない場合 150μ秒
測定(3)
環境
さらにスイッチを多段にしてはかってみます.たとえば,2段スイッチをはさむと次のようになります.
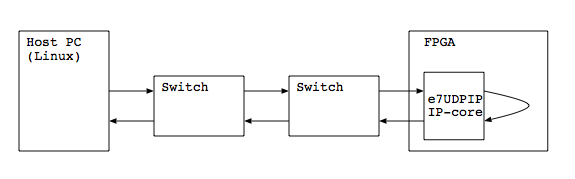
結果: スイッチを2段挟んだ場合
PC <-> FXG16IRM<->GS108(NETGEAR)<->FPGAという構成です.同じスイッチが用意できなかったのはご愛嬌ということで…
ソケットのオープン/クローズを含む場合 203μ秒 ソケットのオープン/クローズを含まない場合 154μ秒
結果: スイッチを3段挟んだ場合
PC <-> FXG16IRM<->GS108(NETGEAR)<->DGS-3420-28TC(D-Link)<->FPGAという構成です.DGS-3420-28TCはGbEと10GbEのスイッチですが,GbEのポートだけを使います.
ソケットのオープン/クローズを含む場合 214μ秒 ソケットのオープン/クローズを含まない場合 200μ秒
結果: スイッチを4段挟んだ場合
さらにもう一段挟んでみます.
PC <-> FXG16IRM<->GS108(NETGEAR)<->DGS-3420-28TC(D-Link)<->LSW-GT-4W(BUFFARO)<->FPGAという構成です.
ソケットのオープン/クローズを含む場合 217μ秒 ソケットのオープン/クローズを含まない場合 201μ秒
結論?
なかなかリニアに増えるものではなく,どこでどう時間を消費しているのかよみとるのが難しいですね…といわけで,結論というほどのものは言えないですが,今回の計測につかった1024のパケットではれば,約8μ秒がパケットバッファを一段とおるのに必要な時間です.FPGA同士を対向させた場合の測定結果がe7udpipのレイテンシを測定してみただったのですが,今回計測した限りでは,ソフトウェアではFPGAに比べて+50μ秒程度のオーバヘッドがかかる,とは言えそうです.

コメント