昨日のe7UDP/IPを使ったFPGA-PC間の通信レイテンシをはかってみたに引き続いて,PC同士の通信レイテンシをはかってみました.
注: あくまで,この数字は今回はかってみたという範囲での測定結果です.測定結果は十分に検証されてものではありませんので,ご容赦ください.
測定環境
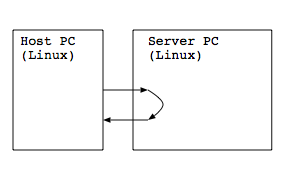
測定環境として次のように2台のPCを対向で接続します.
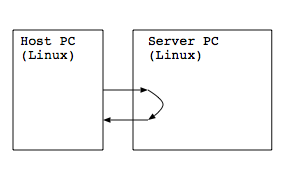
それぞれのスペックは次の通りです.
- Host PC
| CPU | Core i7-3770K 3.50GHz | |
| メモリ | 32GB | |
| OS | CentOS 6.6 (Linux kernel 2.6.32) | |
| ネットワークI/F | Intel 82572EI GbE | |
| コンパイラ | gcc 4.4.7 |
- Server PC
| CPU | Core i3-4130 3.40GHz | |
| メモリ | 16GB | |
| OS | Ubuntu 14.04.2 (Linux kernel 3.13.11) | |
| ネットワークI/F | Intel 82572EI GbE | |
| コンパイラ | gcc 4.8.2 |
もちろん,ちゃんとした測定をするのであれば環境はそろえるべきでしょうが,今回は手持ちの環境ということで…
測定用プログラム
Host PCでは「UDPパケットを送って受信する」プログラムを走らせます.これは,e7UDP/IPを使ったFPGA-PC間の通信レイテンシをはかってみたと同じものを使います.
Server PCでは「受信したパケットを送り返す」プログラムを走らせます.ソースコードは次のとおり.ペイロードの中身のコピーはもちろん確認すらせずに打ち返します.また受信サイズは,送り元にあわせた1024Byteに決めうちしてます.
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <sys/time.h>
int main(int argc, char** argv)
{
int sock;
struct sockaddr_in addr;
struct sockaddr_in dest;
int addrlen = sizeof(dest);
char b0[1024];
addr.sin_family = AF_INET;
addr.sin_port = htons(16385);
addr.sin_addr.s_addr = INADDR_ANY;
sock = socket(AF_INET, SOCK_DGRAM, 0);
bind(sock, (struct sockaddr *)&addr, sizeof(addr));
for(;;){
recvfrom(sock, (void*)b0, sizeof(b0), 0, (struct sockaddr*)&dest, &addrlen);
sendto(sock, (void*)b0, sizeof(b0), 0, (struct sockaddr *)&dest, sizeof(dest));
}
close(sock);
return 0;
}
結果
測定結果です.Host PC側で送受信のたびにソケットのオープン/クローズをするか,ソケットは開きっぱなしものを再利用する(ソケットのオープン/クローズのコストを含まない)かの2パターンではかっています.また,「1回のレイテンシ」は10万回の送受信にかかった時間を10万で割った平均値です.
| ソケットのオープン/クローズを含む場合 | 244μ秒 | |
| ソケットのオープン/クローズを含まない場合 | 216μ秒 |
間にスイッチを挟む
今度は,対向ではなくて間にスイッチを挟んでみます.
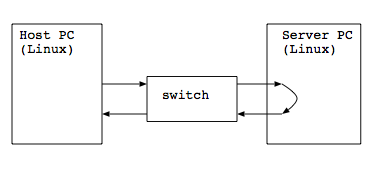
たとえば,1つスイッチを挟むとこんな感じですね.
結果: スイッチを1段挟んだ場合
Host PC <-> FXG16IRM(PLANEX)<->Server PCという構成です.
| ソケットのオープン/クローズを含む場合 | 303μ秒 | |
| ソケットのオープン/クローズを含まない場合 | 271μ秒 |
結果: スイッチを2段挟んだ場合
Host PC <-> FXG16IRM(PLANEX)<->GS108(NETGEAR)<->Server PCという構成です.同じスイッチが用意できなかったのはご愛嬌ということで…
| ソケットのオープン/クローズを含む場合 | 323μ秒 | |
| ソケットのオープン/クローズを含まない場合 | 291μ秒 |
結果: スイッチを3段挟んだ場合
Host PC <-> FXG16IRM<->GS108(NETGEAR)<->DGS-3420-28TC(D-Link)<->Server PCという構成です.DGS-3420-28TCはGbEと10GbEのスイッチですが,GbEのポートだけを使います.
| ソケットのオープン/クローズを含む場合 | 366μ秒 | |
| ソケットのオープン/クローズを含まない場合 | 316μ秒 |
結果: スイッチを4段挟んだ場合
さらにもう一段挟んでみます.
Server PC <-> FXG16IRM<->GS108(NETGEAR)<->DGS-3420-28TC(D-Link)<->LSW-GT-4W(BUFFARO)<->Host PCという構成です.
| ソケットのオープン/クローズを含む場合 | 397μ秒 | |
| ソケットのオープン/クローズを含まない場合 | 339μ秒 |
まとめとこれから?
今回測定した限りでは,PC-FPGA通信のレイテンシに比べるとPC-PCの通信レイテンシは100μ秒〜150μ秒程度の多いという結果になりました.
今後,ですが,ソフトウェアでパフォーマンスチューニングしたときにはどうなるか,というのはみてみたいですね.また,今回の測定ではFPGA側(e7UDP/IPコア)の制約に合わせて1KBのデータの送受信ペイロードを測定しています.これは,ソフトウェアに不利な測定方法であるという点を頭に置いておく必要はありそうです.たとえばペイロード32KBの対向での送受信レイテンシは1267μ秒でした.1KBの送受信レイテンシは216μ秒でしたが,1267 < 32 * 216 ですので,全然リニアではありませんね.

コメント